

Transaction management#
This document presents several advanced recipes related to transaction management in the Ingest API. Please read the following document first:
Transactions (CONCEPTS)
Planning multiple transactions#
To improve workflow stability, particularly during failures, the system supports distributed transactions. This method is essential for ensuring stable ingests. Transactions were initially discussed in the section Simple Workflow Example. This section further explores the advantages of this method by detailing the planning and management of parallel transactions.
All rows are ingested into the data tables within the scope of transactions. Once a transaction is committed, all relevant contributions remain in the destination tables. Conversely, if the transaction is aborted, the rows are removed. The transaction abort operation (Commit or abort a transaction) won’t revert all modifications made to tables. It will only remove rows ingested within the corresponding transaction. For instance, any tables created during transactions will stay in Qserv. Any chunk allocations made during transactions will also stay. Leaving some tables empty after this operation won’t confuse Qserv even if the tables remain empty after publishing the database.
When designing a workflow for a specific catalog or a general-purpose workflow, it is crucial to consider potential failures during ingests. Estimating the likelihood of encountering issues can guide the decision-making process for planning the number and size of transactions to be started by the workflow. Here are some general guidelines:
If the probability of failures is low, it is advisable to divide the input dataset into larger portions and ingest each portion in a separate transaction.
Conversely, if the probability of failures is high, using smaller transactions may be more appropriate.
Another approach is to create a self-adjusting workflow that dynamically decides on transaction sizes based on feedback from previous transactions. For instance, the workflow could begin with several small transactions as probes and then progressively increase or decrease the number of contributions per transaction based on the results. This technique has the potential to enhance workflow performance.
Other factors influencing the transaction planning process include:
Availability of input data: Contributions to the catalogs may arrive incrementally over an extended period.
Temporary disk space limitations: The space for storing intermediate products (partitioned CSV files) may be restricted.
Qserv configuration: The number of worker nodes in the Qserv setup can impact the workflow design.
What is a resonable number of transactions per catalog ingest?#
When planning ingest activities, consider the following global limits:
The total number of transactions per Qserv instance is capped by an unsigned 32-bit number. The transaction identifier
0is reserved by the Ingest System, so the maximum number of transactions is4294967295.The total number of transactions per table is limited to
8192due to the MySQL partition limit. Practically, opening more than100transactions per database is not advisable because of the overheads associated with MySQL partitioning.
Another factor to consider is the implementation of transactions. The Ingest system directly maps transactions
to MySQL table partitions. Each partition is represented by two files in the filesystem of the worker where
the corresponding table resides (in the current implementation of Qserv, the data tables use the MyISAM storage engine):
<table-name>#p<transaction-id>.MYD: The data file of the MySQL partition.<table-name>#p<transaction-id>.MYI: The index file of the MySQL partition.
In the extreme case, the number of files representing chunked tables would be roughly equal to the total number of
chunks multiplied by the number of transactions open per catalog. For example, if there are 150,000 chunks in
a catalog and 10 transactions are open during the catalog ingest, the total number of files spread across
all workers could be as many as 3,000,000. If the number of workers is 30, then there would be
approximately 100,000 files per worker’s filesystem, all in a single folder.
In reality, the situation may not be as severe because the chunks-to-transactions “matrix” would be rather sparse,
and the actual number of files per directory could be about 10 times smaller. Additionally, all MySQL table partitions will
be eliminated during the catalog publishing phase. After that, each table will be represented
with the usual three files:
<table-name>.frm: The table definition file.<table-name>.MYD: The data file.<table-name>.MYI: The index file.
Nevertheless, it is advisable to avoid opening thousands of transactions per catalog ingest, even though the hard
limit for MySQL partitions per table might seem quite high at 8192.
Parallel transactions#
This section covers some parallel ingest scenarios that may increase the overall performance of a workflow.
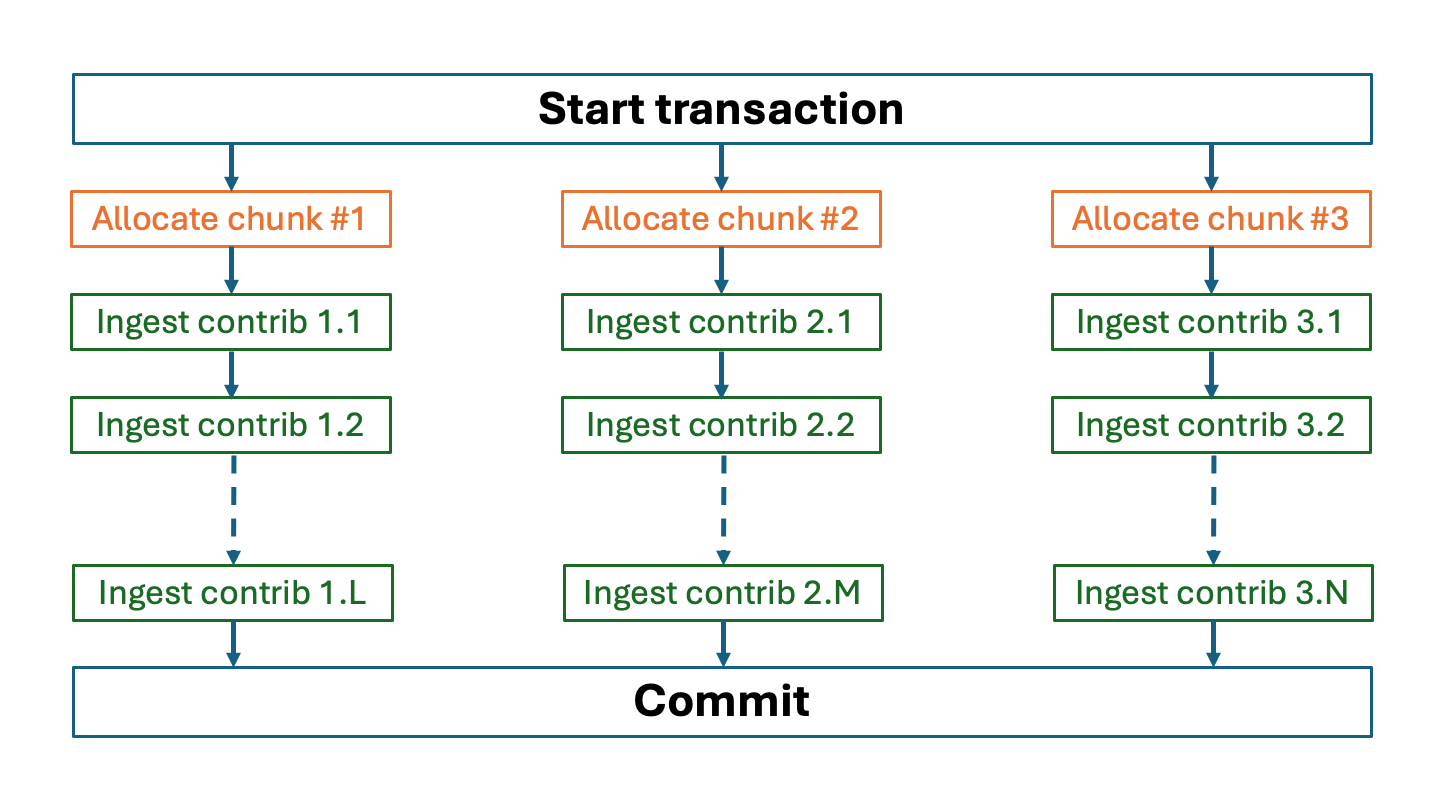
Ingesting chunks in parallel within a single transaction#
This is the simplest scenario that assumes the following organization of the workflow:
Sequential: Start a common transaction before uploading the first chunk.
Parallel: For each chunk:
Sequential: Allocate a chunk
Sequential: Ingest contributions into each chunk.
Sequential: Commit the common transaction after all contributions are successfully uploaded.
The following diagram illustrates the idea:
Things to consider:
The chunk allocation operations are serialized in the current version of the system. This may introduce indirect synchronization between parallel chunk-specific ingests. The total latency incurred by such synchronization is the latency of allocating one chunk multiplied by the number of chunks.
The proposed scheme may not be very efficient if the number of chunks is large (heuristically, many thousands) while chunk contributions are small. In this case, the latency of the chunk allocation requests may become a significant factor limiting the performance of the workflow.
Any failure to ingest a contribution will result in aborting the entire transaction. This can significantly impact the workflow’s performance, especially if the amount of data to be ingested is large.
Best use:
When the number of chunks is small and the amount of data to be ingested into each chunk is large, or if the amount of data or the number of contributions to be ingested into each chunk is large. In this case negative effects of the chunk allocation latency are negligible.
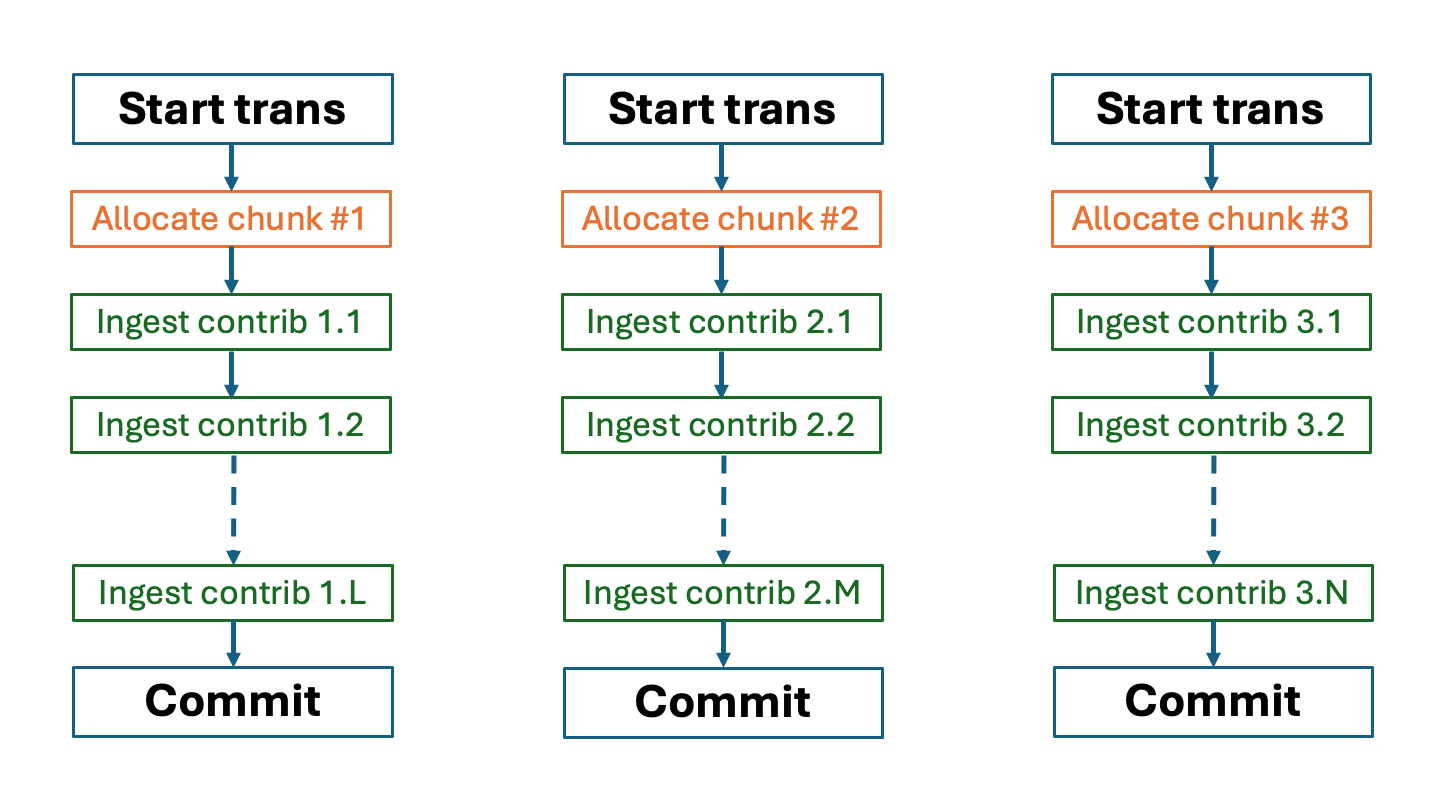
Ingesting chunks in parallel within dedicated transactions#
This is a more complex scenario that assumes the following organization of the workflow:
Parallel: For each chunk do the following:
Sequential: Start a separate transaction dedicated for ingesting all contributions of the chunk.
Sequential: Allocate the chunk and ingest all contributions into the chunk.
Sequential: Commit the transaction after all contributions into the chunk are successfully uploaded.
The following diagram illustrates the idea:
Things to consider:
Although this scheme assigns each chunk to a dedicated transaction, it is not strictly necessary. The Ingest system allows allocating the same chunk and ingesting contributions into that chunk from any (or multiple) transactions. Just ensure that the same set of rows (the same set of contributions) is not ingested within more than one transaction. This rule applies to any workflow regardless.
Failures in one chunk transaction will not affect chunk contributions made in the scope of other transactions. This is a significant advantage of this scheme compared to the previous one.
Best use:
When ingesting a large dataset, it can be divided into independently ingested groups based on chunks. Transactions offer a mechanism to handle failures effectively.
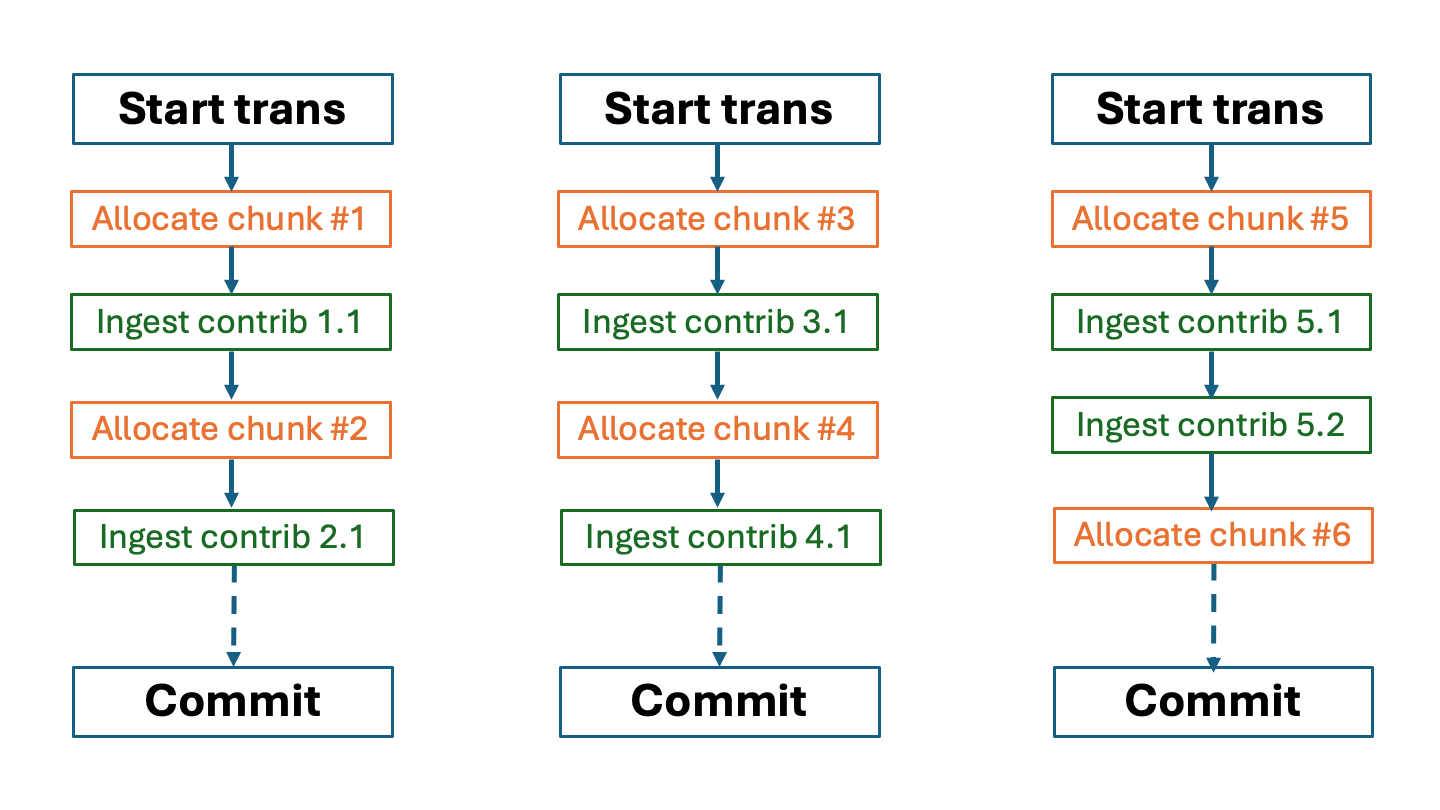
Scattered ingest of chunk contributions within multiple transactions#
Workflow organization:
Parallel: For each transaction do the following:
Sequential: Start a transaction dedicated for ingesting a subset of contributions of any chunks that may be related to cteh contributions of teh subset.
Sequential: For each contribution in the subset:
Sequential: Allocate a chunk as needed for the contribution.
Sequential: Ingest the contributions into the chunk.
Sequential: Commit the transaction after ingesting all contributions in the subset.
The following diagram illustrates the idea:
Best use:
When the workflow is designed to ingest a large dataset where data are streamed into the workflow. This scenario is particularly useful when the data are not available in a single file or when the data are generated on-the-fly by some external process.
Tip
One can combine the above scenarios to create a more complex workflow that meets the specific requirements of the ingest process.
Aborting transactions#
The concept of distributed transactions was introduced in the section Transactions. Transactions are a fundamental mechanism for ensuring the consistency of the ingest process. The system allows aborting transactions to revert the effects of all contributions made to the catalogs within the scope of the transaction. This operation is particularly useful when the ingest process encounters an issue that cannot be resolved by the system automatically, or when the failure leaves the data or metadata tables in an inconsistent state. Transactions are aborted using the following service:
Reasons to abort#
There are two primary reasons for aborting a transaction, detailed in the subsections below.
Communication Failures#
If any communication problem occurs between the workflow and the system during a contribution request, the workflow must unconditionally abort the corresponding transaction. Such problems create uncertainty, making it impossible to determine if any actual changes were made to the destination tables.
This rule applies universally, regardless of the method used for making the contribution request (by reference, by value, synchronous, asynchronous, etc.).
Ingest System Failures#
Unlike the previously explained scenario, this scenario assumes that the workflow can track the status of attempted contribution requests. The status information is reported by the ingest system. The workflow can detect a failure in the response object and decide to abort the transaction. However, the analysis of the failure is done slightly differently for synchronous and asynchronous requests.
The algorithm for the synchronous requests is rather straightforward. If the attribute status of the response object
indicates a failure as status=0, the workflow must analyze the retry-allowed flag in Contribution descriptor (REST).
If the flag is set to 0, the transaction must be aborted. If the flag is set to 1, the workflow can retry the contribution request
within the scope of the same transaction using the following service:
The algorithm for the asynchronous requests is a bit more complex. The response object for the contribution submission request does not contain
the actual completion status of the request. If the request submission was not successful as indicated by status=0, it means the request was incorrect or
made in a wrong context (no transaction open, non-existing table, etc.). In this case, the workflow must abort the transaction.
Otherwise (the response object has status=1), the actual status of the contribution request can be obtained later by polling the system
as explained in the section:
Status of the contribution requests (CONCEPTS)
The REST services explained in this section return the contribution descriptor object that contains the status of the contribution request. The workflow must first check if a contribution has finished (or failed) or if it’s still in progress (or in the wait queue of the processor).
Contribution descriptor (REST)
Possible values of the attribute status (Note this is an attribute of the contribution itself not the completion status of teh REST request)
are explained in the above-mentioned document. Any value other than IN_PROGRESS indicates that the contribution request has finished (or failed).
Should the request fail, the workflow must then analyze the flag retry-allowed as explained above.
What happens when a transaction is aborted?#
Aborting a transaction is a relatively quick operation. The primary change involves the removal of MySQL table partitions associated with the transaction. The following table files on disk will be deleted:
<table-name>#p<transaction-id>.MYD: The data file of the MySQL partition.<table-name>#p<transaction-id>.MYI: The index file of the MySQL partition.
All queued or in-progress contribution requests will be dequeued or stopped. The final status of the requests will be either CANCELLED (for requests
that were still in the queue) or some other failure state depending on the processing stage of a request. The system will not attempt to process
them further.
What to do if a transaction cannot be aborted?#
It’s possible that the system will not be able to abort a transaction. For example, if one of the workers is down or is not responding to the abort request.
In such cases, the status of the transaction will be IS_ABORTING or ABORT_FAILED as explained in the section:
Transaction states (CONCEPTS)
If the transaction cannot be aborted, the workflow developer must be prepared to handle the situation. There are a few options:
The workflow may be programmed to retry the abort operation after a certain timeout.
If retrying doesn’t help, the user of the workflow should contact the Qserv administrators to resolve the issue.