

Types of tables in Qserv#
There are two types of tables in Qserv:
regular (fully replicated)
partitioned (distributed)
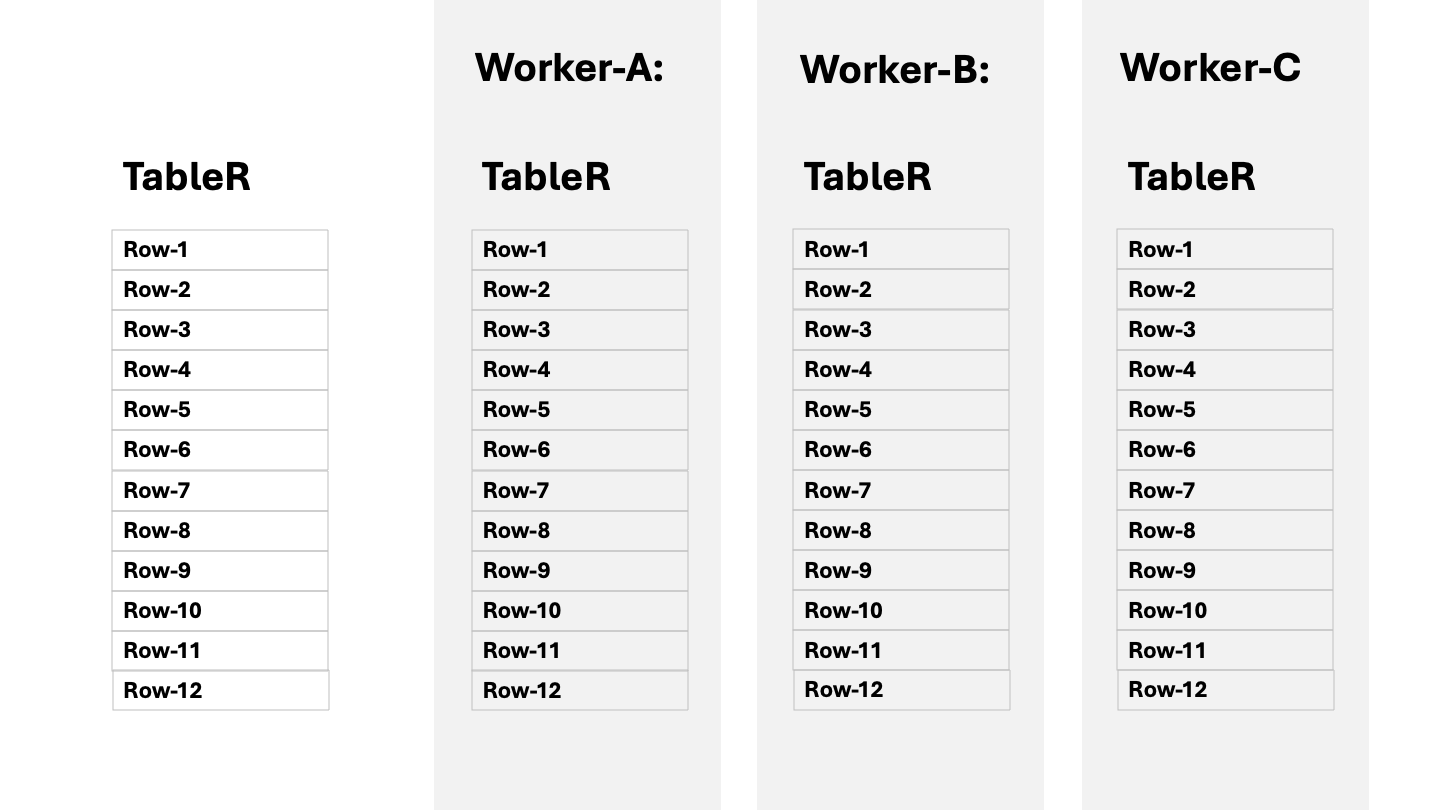
A copy of the regular table exists at each worker node. Tables of this type are relatively small so that they can fit on disk at each worker. The tables are usually meant to store the metadata or the reference data for the large partitioned tables. The following diagram illustrates the concept:
The partitioned tables are distributed across the workers. These tables are much larger than the regular tables and they can’t fit on disk at each worker. Each such table is horisontally (by rows) partitioned into the so called chunks (or chunk tables). Each chunk table is a separate table that is stored on the MySQL server of a worker. Depending on values of the partitioning parameters (specifically on th number of stripes) a catalog may have from 10,000 to over 100,000 chunks. The names of the chunk tables are based on the name of the original table, the chunk number and the optional “FullTableOverlap” suffix after the base name of the table. See the following section for more information on the naming convention of the tables in Qserv:
Each chunk table has a subset of the rows of the original table. A superposition of rows from all the chunk tables of the same Qserv table is equal to a set of rows in the original (base) table. The following diagram illustrates the concept:
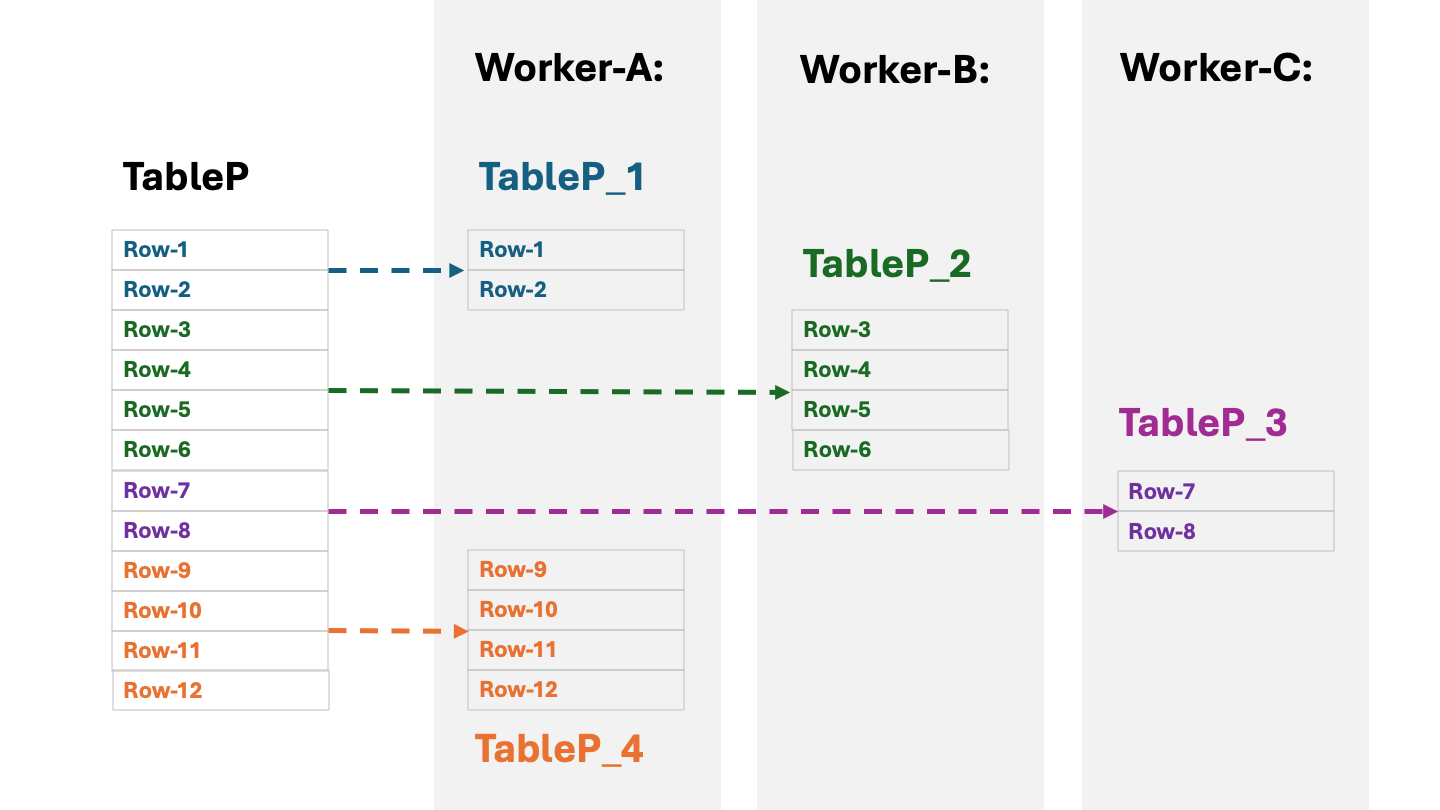
Note that each chunk of the partitioned table maps to rectangular sector of the Sky based on the spatial coordinates system adopted by Qserv. Spatial coordinates of all rows within a chunk table are all found within the spatial area of the chunk. The spatial areas of different chunks never overlap.
Note
The chunk overelap table includes a “halo” of rows from the neighboring chunks. The size of the overlap is defined by the overlap parameter of the table. The overlap is used to ensure that the rows that are close to the chunk boundary are not missed by the so called “near-neighbour” queries. These table are explained late rin this section.
The chunk tables are made by the partitioning process that is documented in:
The partitioned tables are further classified into the following subtypes:
director tables
dependent tables, which are further classified into:
simple (1 director)
ref-match (2 directors)
The director tables are the tables in which each row has a unique identifier which is similar to the primary key in the relational algebra. The dependent tables have rows which depend on the rows of the corresponding director tables via the foreign-like key referencing the corresponing primary key. The simple tables have only one director table, while the ref-match tables have two director tables. The ref-match tables are used to store the matches between the objects of the two different tables. The following diagram illustrates these concepts:
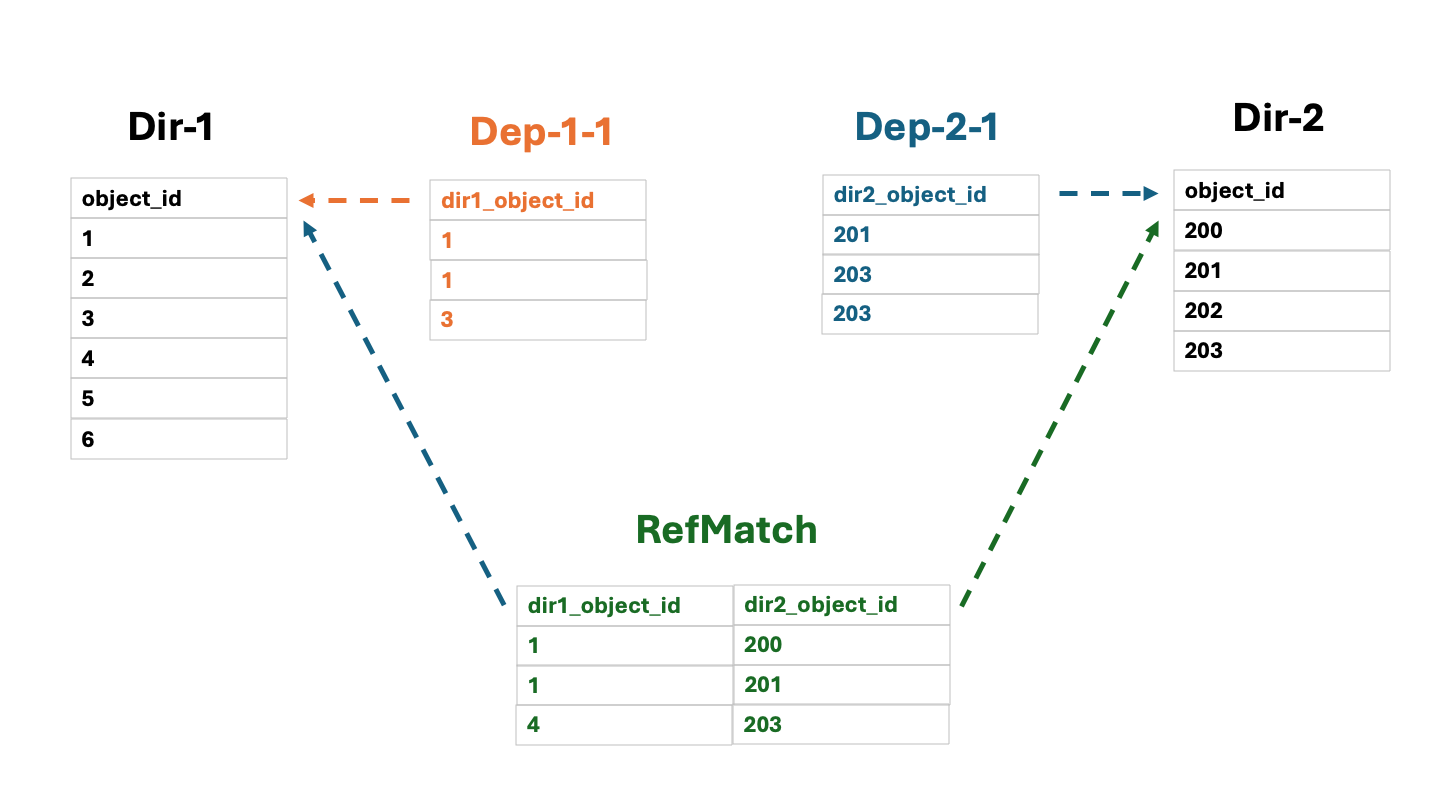
The director tables may not have any dependent tables. Each such director is useable and queriable by itself. The dependent tables must have the corresponding director tables. Same rules apply to the ref-match tables.
Each chunk table of the director table has the corresponfing chunk overlap table. The overlap table includes a subset of rows from the chunk table and a “halo” of rows from the neighboring chunks. The size of the overlap is defined by the overlap parameter of the table. The idea of the overlap is illustrated in the following diagram:
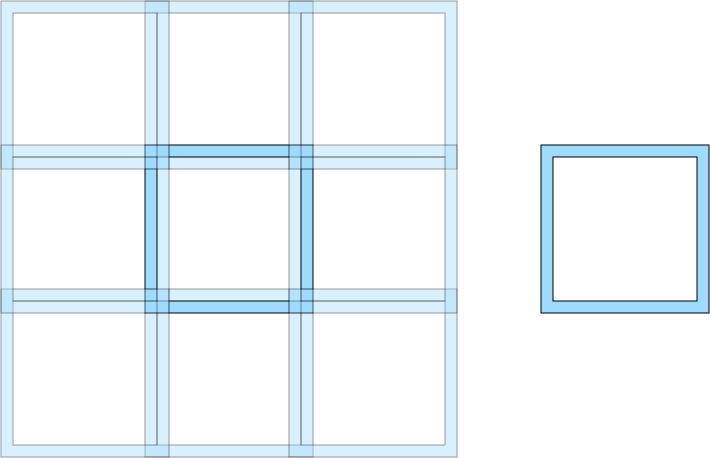
The diagram shown sub-chunk boundaries within the chunk table.