

Transactions#
The distributed transaction mechanism is a crucial technology in the Qserv Ingest system. It enables incremental updates to the data and metadata while maintaining the consistency of ingested catalogs. Transactions also facilitate high-performance ingest activities in a distributed environment. When used correctly, transactions can significantly enhance the parallelism of ingest workflows. Note that transactions are not visible to end users.
Transactions are open in a scope of a database. It’s a responsibility of the workflows to manage transactions as needed for the ingest activities using the following REST services:
Transaction management (REST)
Isolation and parallelism#
The first role of the transaction is to provide the isolation of the ingest activities. The transactions allow for the parallel ingest of the data into the tables located at the many workers of the Qserv cluster, and into the same table located at the same worker. The transactions are started and commited independently of each other. The transactions are not visible to the users and are not used for the user queries.
To understand why the transactions help to increase the level of parallelism of the ingest activities, read the last section on this page:
Implementation Details (CONCEPTS)
Row tagging#
The second role of the transactions is to implement the tagging mechanism for the ingested data. All rows
ingested into to the data tables and the director index tables are tagged with the transaction identifiers
that is unique for each transaction. Hence, all contribution requests made into the tables via this API are
associated with a specific identifier. The identifiers are usually sent in the service request and response objects
in an attribute transaction_id. As an example of the attribute, see a description of the following REST service:
An effect of such tagging can be seen as a special column called qserv_trans_id that is automatically added by
the Ingest system into the table schema of each table. In the current implementation of the system, this is the very
first column of the table. The column is of the UNSIGNED INT type and is not nullable. The column is visible
to Qserv users and is queriable. Here is an illustration of a query and the corresponding result set illustrating the concept:
SELECT `qserv_trans_id`, `objectId`,`chunkId`
FROM `dp02_dc2_catalogs`.`Object`
WHERE `qserv_trans_id` IN (860, 861);
+----------------+---------------------+---------+
| qserv_trans_id | objectId | chunkId |
+----------------+---------------------+---------+
| 860 | 1249546586455828954 | 57871 |
| 860 | 1249546586455828968 | 57871 |
. . . .
| 861 | 1252546054176403713 | 57891 |
| 861 | 1252546054176403722 | 57891 |
+----------------+---------------------+---------+
Note
The database administrator can decide to drop the column from the table schema if there is a need to save the space in the table. The column is not used by Qserv for any other purposes than the ingest activities. And once the ingest is completed, the column is not needed anymore except for Q&A-ing the data, bookeeping and data provenance.
Checkpointing#
Transactions also provide a checkpointing mechanism that allows rolling back to a prior consistent state of the affected tables should any problem occur during the ingest activities. Transactions may span across many workers and tables located at the workers. It’s up to the workflow to decide what contributions to ingest and in what order to ingest those in the scope of each transaction.
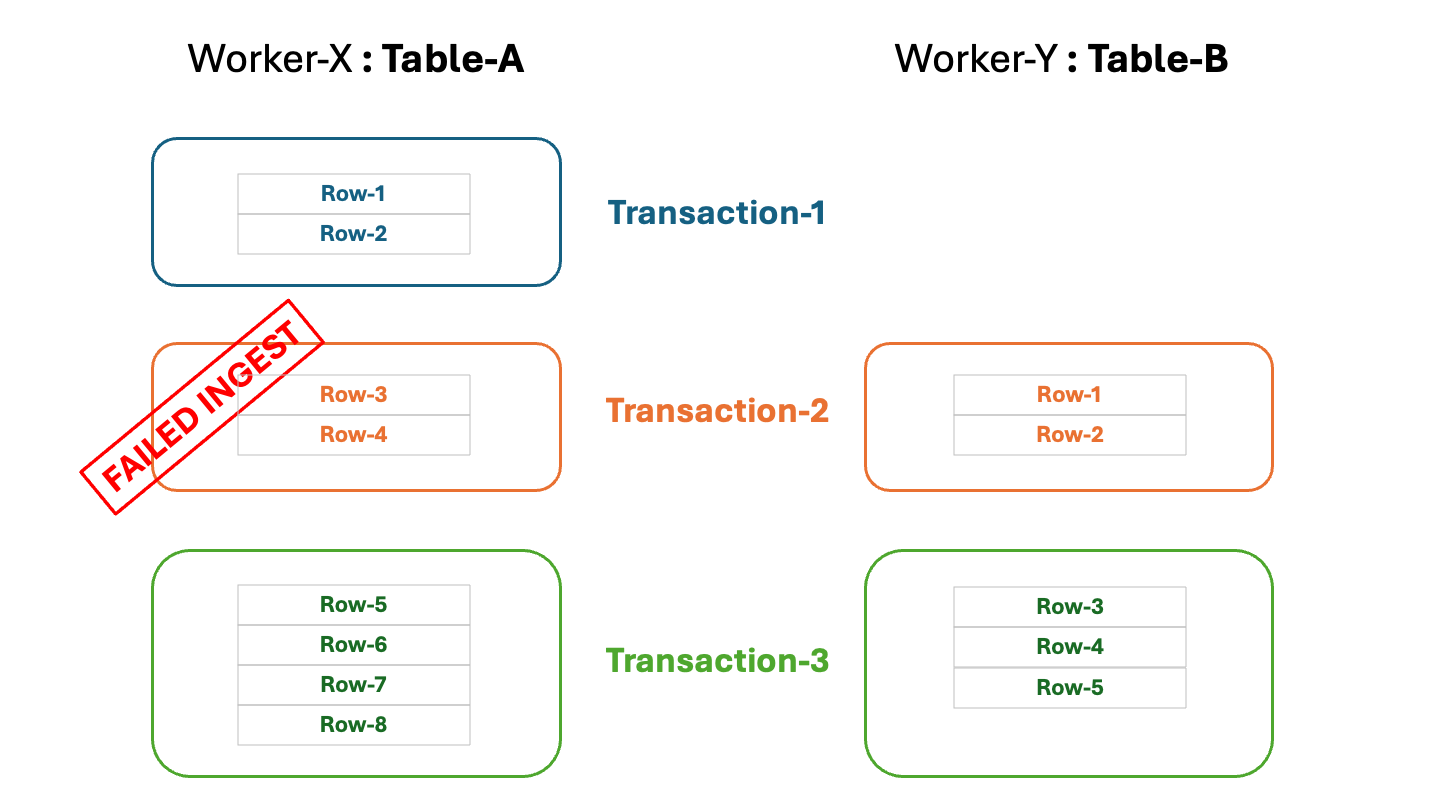
The following diagram illustrates the concept of the transactions in Qserv. There are 3 transactions that are started and
commited sequentially (in the real life scenarios the transactions can be and should be started and commited in parallel,
and indepedently of each other). Data are ingested into two separate table located at 2 workers. The diagram also shows
a failure to ingest the data into table Table-A at Worker-X in a scope of Transaction-2:
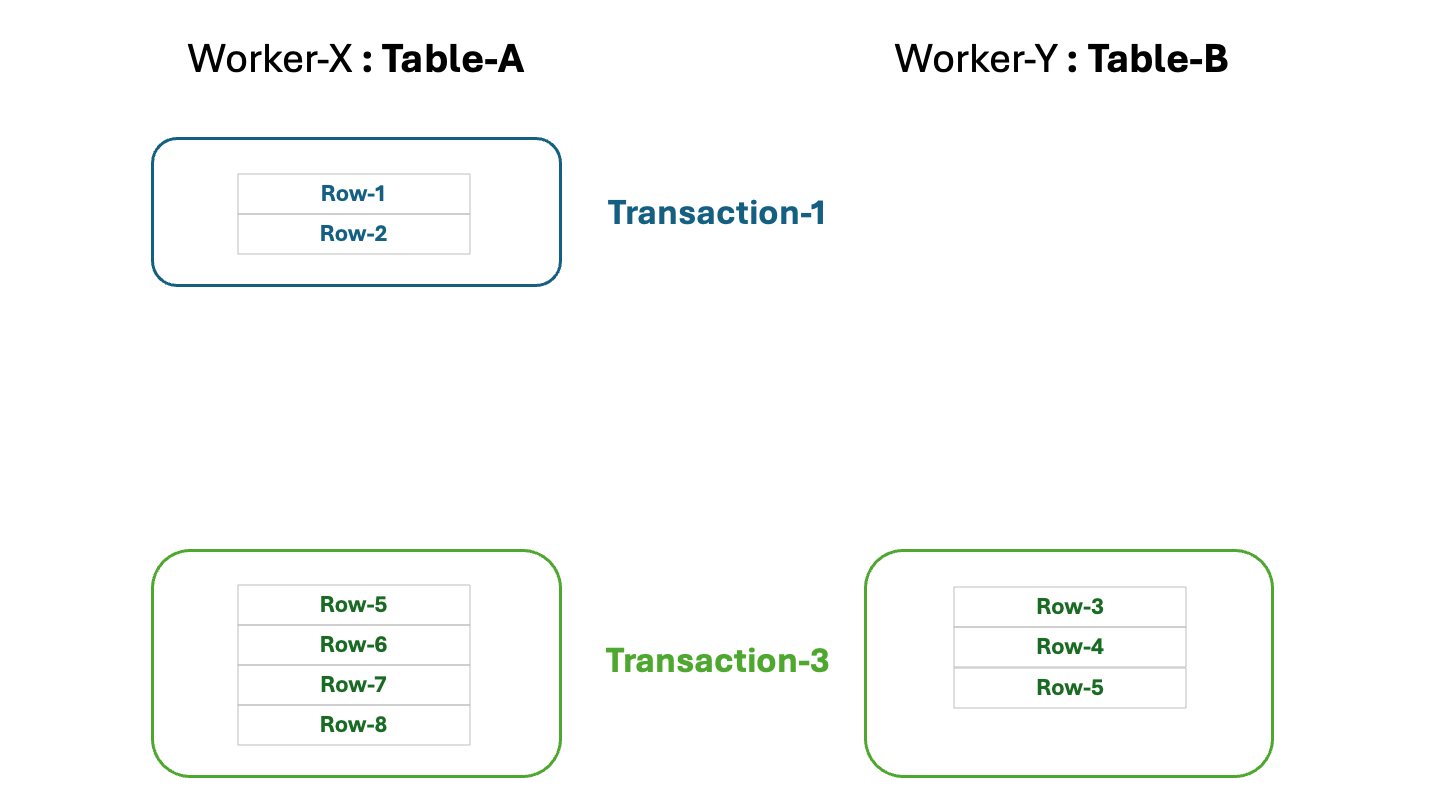
At this point the table Table-A at Worker-X is found in an inconsistent state. The workflow can decide to roll back
the failed transaction and to re-try the ingest activities in a scope of the new transaction. The rollback is performed by
the worker ingest service:
Also read the following document to learn more about the transaction abort:
Aborting transactions (ADVANCED)
Removing the failed transaction would result in the following state of the tables, which is clean and consistent:
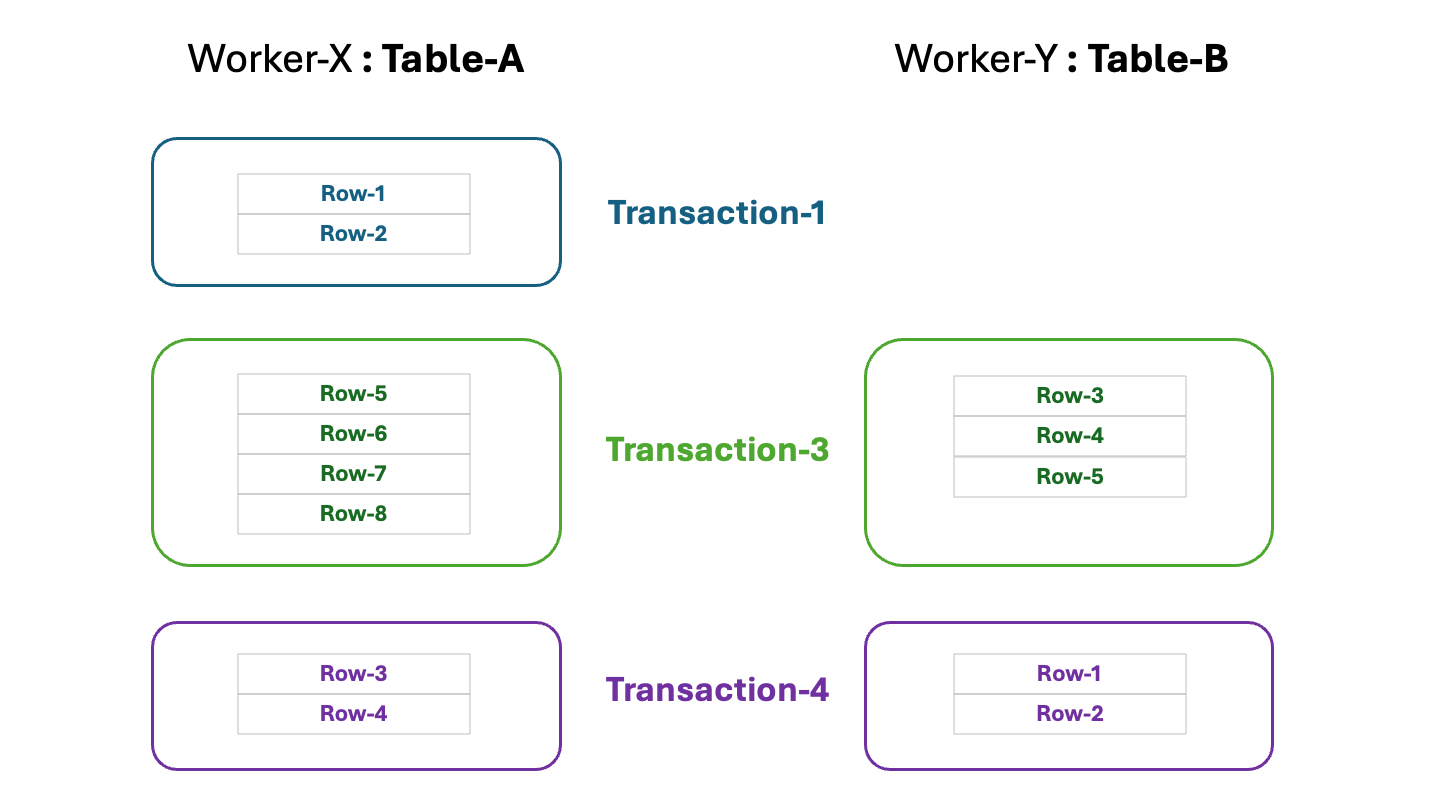
After that, the workflow can re-try ALL ingest activities that were meant to be done in a scope of the previously failed transaction by starting another transaction. If the ingest activities are successful, the tables will be in the consistent state:
Transaction status and state#
Each transaction is in a well-defined state at each moment of time. The state is a part of the broader collection if the transaction attributes called the transaction status. All of this can be obtained by calling services documented in the following section:
Status of a transaction (REST)
Transaction states (REST)
The services provide a flexible filtering mechanism for finding the transactions of interest in various scopes and states and reporting the information at different levels of details as needed by the workflows or other applications.
These are just a few typical applications for this information in a context of the workflows:
Dynamic transaction management (versus the static management where all transactions would be started at once):
Starting the limited number of transactions at the beginning of the ingest
Monitoring the progress and performance of the transactions
Committing transactions where all table contributes were successfully ingested
Starting new transactions to load more contributions to meet the performance goals
Locating the failed transactions and re-trying the ingest activities in a scope of the new transactions.
Locating failed table contribution requests that were made in a scope of a transaction to see if it’s possible to retry the contributions w/o aborting the transaction.
Building a Web dashboard.
Contexts#
When starting (or finishing a transaction) using the corresponding services (see below) a workflow may optionally
attach an piece of arbitrary workflow-defined information (the JSON object) to the transaction. The object is called
the context. It will be stored within the Replication/Ingest system’s database and be associated with the transaction.
The object could be as large as 16 MB. In effect, the context is a part of the transaction’s persistent state.
The initial version of the context object is passed along the transaction start request in the attribute context:
Start a transaction (REST)
The context object may also be updated when aborting or committing a transaction by:
Contexts are also retrieved by the status retrieval services:
Status of a transaction (REST)
The workflow may use the contexts for the following reasons:
Store the information on the input contributions made in a scope of a transaction to be used later for the recovery from the failures. The information may include locations of the input files, as well as any other information allowing to retry the contributions. Making the workflows to depend on the contexts may simplify the implementation of the workflows by allowing to avoid the need to store the information in the external databases or files. Altogether, the contexts may improve robustness of the workflows.
Store the information for the purpose of internal bookkeeping that would be independent of the user workflow’s infrastructure or environment.
Store the additional information to be used as a source of metadata for data provenance systems.
Obviously, the workflow implementation may have its own mechanism for that, and it probably should. However, attaching the metadata to transactions in the persistent state of the system along with the transactions has a few important benefits. In particular, it guarantees consistency between transactions and contexts. Secondly, it provides the precise timing for the ingest operations (the start and finish times are measured by the Ingest system at the right moments). Thirdly, the information may be seen from the general-purpose Web Dashboard application of Qserv and could also be used by the database support teams for building various metrics on the performance of the Qserv Ingest system.
Implementation Details#
The Qserv transactions are quite different from the ones in the typical RDBMS implementations. Firstly, they are not designed as an an isolation mechanis for executing user queries, and the are not visible to Qserv users. In Qserv, tables that are being ingested are not seen or queriable by the users anyway. The main purpose of the transactions in Qserv is to allow for the incremental updates of the distributed state of data in Qserv across many (potentially - hundreds of) workers. Each worker runs its own instance of the MySQL/MariaDB server which is not aware of the of the others. Some might say that transactions are associated with vertical slices of rows in the tables that are located at the workers.
The second technical problem to be addressed by the transactions is a lack of the transaction support in the MyISAM table engine that is used in Qserv for the data tables. The MyISAM engine is used in Qserv due to it ssimplicity and high performance. Unfortunately, failuires while ingesting data into the MyISAM tables can leave the table in a corrupted state. The transactions provide a mechanism allowing to roll back the tables to a consistent state in case of the failures. The current implementation of the transactions in Qserv is based on the MySQL/MariaDB partitions:
Warning
When the catalog is being published, the partitioned MyISAM tables are converted to the regular format.
This operation is performed by the Qserv Ingest system.
The conversion is a time-consuming operation and may take a long time to complete for
a single table. An observed performance of the operation per table is on a scale of 20 MB/s to 50 MB/s.
However, a typical catalog will have thousands of such chunk tables which would be processed in parallel
at all workers of the Qserv cluster. The resulting performance of the conversion would be on a scale of
many GB/s, and the operation would be completed in a reasonable time.
A definition of the reasonable time is given rather loosely here. An overall idea is that such conversion should be on the same scale (smaller) as the table ingest per se. A similar philosophy is applied to other data management operations in Qserv besides the ingest.
From a prospective of the workflows, these are the most important limitations of the transactions:
Transaction identifiers are the 32-bit unsigned integer numbers. The maximum number of the transactions that can be started in the system is 2^32 - 1 = 4,294,967,295. The transactions are not re-used, so the number of the transactions that can be started in the system is limited by the number of the unique transaction identifiers that can be generated by the system.
The transaction with the identifier
0is reserved for the system for the so called default transaction. The workflows can’t ingest any contributions in a context of that transaction, or manage this special transaction.MySQL tables only allow up to
8,000partitions per table. This is a limitation of the MySQL/MariaDB partitioning mechanism. And there is a certain overhead in MySQL for each partition. Hence, it’s not recommended to start more than1,000transactions during the ingest.
Transaction numbers directly map to the partition identifiers of the MySQL/MariaDB partitioned tables. Here is an example of a few chunk tables of a catalog that is still being ingested:
-rw-rw----+ 1 rubinqsv gu 4868 Sep 10 20:48 gaia_source_1012.frm
-rw-rw----+ 1 rubinqsv gu 48 Sep 10 20:48 gaia_source_1012.par
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1012#P#p0.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1012#P#p0.MYI
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1012#P#p1623.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1012#P#p1623.MYI
-rw-rw----+ 1 rubinqsv gu 31000308 Sep 10 20:48 gaia_source_1012#P#p1628.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 11 19:49 gaia_source_1012#P#p1628.MYI
-rw-rw----+ 1 rubinqsv gu 4868 Sep 10 20:48 gaia_source_1020.frm
-rw-rw----+ 1 rubinqsv gu 48 Sep 10 20:48 gaia_source_1020.par
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1020#P#p0.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1020#P#p0.MYI
-rw-rw----+ 1 rubinqsv gu 51622084 Sep 10 20:48 gaia_source_1020#P#p1624.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 11 19:49 gaia_source_1020#P#p1624.MYI
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1020#P#p1630.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1020#P#p1630.MYI
-rw-rw----+ 1 rubinqsv gu 4868 Sep 10 20:47 gaia_source_1028.frm
-rw-rw----+ 1 rubinqsv gu 48 Sep 10 20:47 gaia_source_1028.par
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1028#P#p0.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1028#P#p0.MYI
-rw-rw----+ 1 rubinqsv gu 739825104 Sep 10 20:48 gaia_source_1028#P#p1625.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 11 19:49 gaia_source_1028#P#p1625.MYI
-rw-rw----+ 1 rubinqsv gu 0 Sep 10 20:46 gaia_source_1028#P#p1629.MYD
-rw-rw----+ 1 rubinqsv gu 2048 Sep 10 20:46 gaia_source_1028#P#p1629.MYI
This snapshot was taken by looking at the MariaDB data directory at one of the Qserv workers. Note that the tables
are partitioned by the transaction numbers, where the transaction identifiers are the numbers after the #P# in
the file names.